導入背景:非エンジニアでも使える社内向け文字起こしツールを内製
この記事でわかること
- Google公式API(Gemini 1.5 Pro / Cloud Speech-to-Text)を使った実装の全体像
- WAV/MP3/MP4 を対象に、長尺(~2時間超)でもAPI制限に該当しにくい分割戦略
- EXE化して配布し、非エンジニアがダブルクリックで使える運用
ポイント要約
- GUIはTkinter、ビルドはPyInstaller
- Gemini:30分×FLACチャンク(300MB上限回避)
- STT:55秒×FLACモノラル(10MB / 60秒上限回避)
- MP4はffmpegで音声抽出してから同じフローへ
前提・準備(5分)
必要なもの
- Windows 11(ユーザー側は Python 不要/EXE配布)
- GCP プロジェクト(課金有効)
- サービスアカウント鍵
service_account.json ffmpeg.exeとffprobe.exe
設定イメージ
以下の画像は、実際の配布フォルダ構成です。Transcriber.exe、service_account.json、ffmpeg.exe、ffprobe.exe が同じフォルダに配置されています。
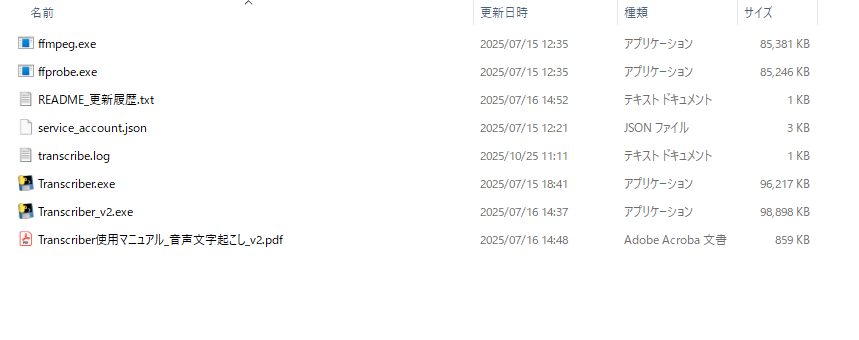
配布フォルダの構成例
アーキテクチャ(簡易図)
[GUI(Tkinter)] → [分割/変換(pydub+ffmpeg)] → [Gemini or STT API] → [TXT/SRT出力]
↑ MP4は先に音声抽出(ffmpeg) ↑
- Gemini:FLAC(30分)を
inline_dataで送信 - STT:FLAC(55秒, mono)を長時間非同期APIへ送信
使い方(利用者向け)
1
ファイル選択
Transcriber.exe をダブルクリックし、対象ファイル(WAV/MP3/MP4)を選択します。
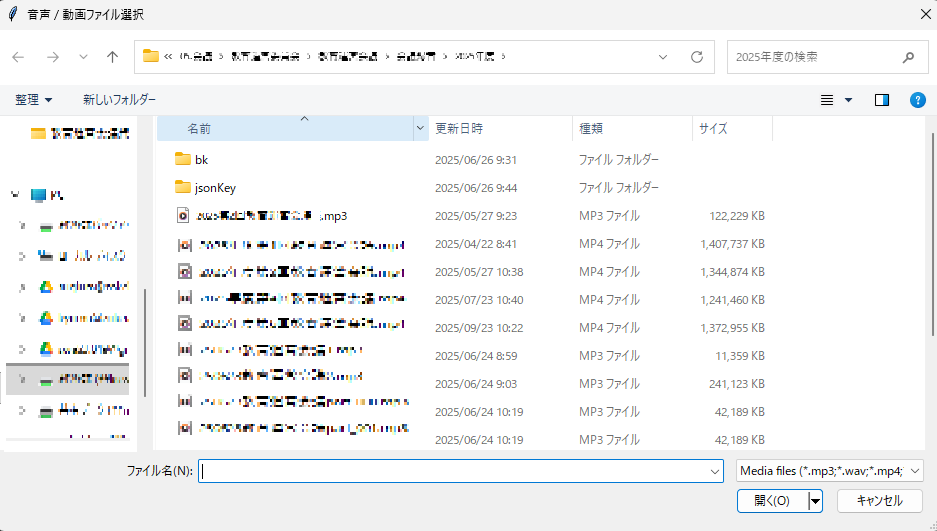
ステップ1: ファイル選択ダイアログ
2
エンジン選択
「Gemini」 または 「Cloud STT」 ボタンでエンジンを選択します。
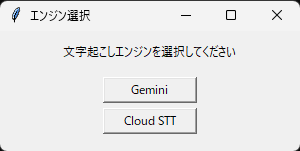
ステップ2: エンジン選択
3
実行確認
設定内容を確認し、実行します。
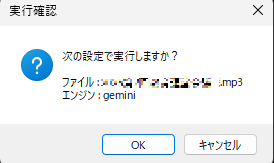
ステップ3: 実行確認ダイアログ
4
完了
処理完了後、同ディレクトリに 元ファイル名_gemini.txt/.srt または 元ファイル名_stt.txt/.srt が出力されます。
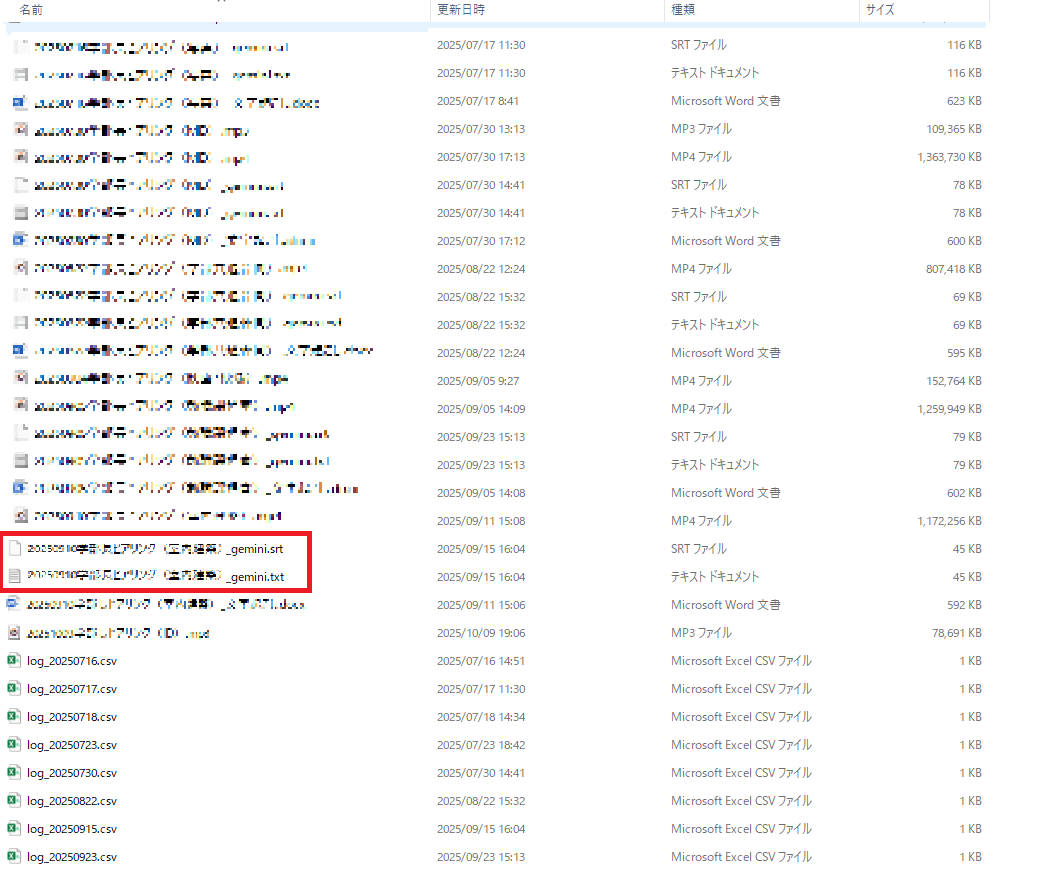
ステップ4: 完了
実装のコア(コピー可能コード)
構成:main.py(起動) / gui_tk.py(ダイアログ) / transcriber.py(処理本体)
依存パッケージ:
pip install pydub ffmpeg-python google-generativeai google-cloud-speech tqdm pysrt pyinstaller
main.py
"""
main.py - エントリーポイント(Tkinter GUI + Gemini / Cloud STT)
"""
import logging, sys, traceback, tkinter as tk
from tkinter import messagebox
import gui_tk as gui
from transcriber import Transcriber
logging.basicConfig(
filename="transcribe.log", level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s", datefmt="%Y-%m-%d %H:%M:%S",
)
def _show_error(msg: str) -> None:
root = tk.Tk(); root.withdraw()
messagebox.showerror("エラー", msg)
root.destroy()
def main() -> None:
try:
file_path = gui.ask_audio_file()
engine = gui.ask_engine()
gui.confirm(file_path, engine)
Transcriber(file_path, engine).process()
stem = file_path.stem
gui.popup_finish([f"{stem}_{engine}.txt", f"{stem}_{engine}.srt"])
except gui.UserCanceled:
logging.info("User canceled the operation."); sys.exit(0)
except Exception as exc:
logging.error("Unexpected error:\n%s", traceback.format_exc())
_show_error(f"エラーが発生しました:\n{exc}\n\n詳細は transcribe.log をご確認ください。")
sys.exit(1)
if __name__ == "__main__":
main()gui_tk.py
"""
gui_tk.py - Tkinter 版 3 ステップダイアログ
"""
from pathlib import Path
import tkinter as tk
from tkinter import filedialog, messagebox
from contextlib import contextmanager
class UserCanceled(Exception): pass
@contextmanager
def hidden_root():
root = tk.Tk(); root.withdraw()
try: yield root
finally: root.destroy()
def ask_audio_file() -> Path:
with hidden_root():
fp = filedialog.askopenfilename(
title="音声 / 動画ファイル選択",
filetypes=[
("Media files", "*.mp3 *.wav *.mp4 *.mov *.mkv *.avi"),
("All files", "*.*"),
],
)
if not fp: raise UserCanceled
return Path(fp)
def ask_engine() -> str:
choice: list[str] = []
def _set(val: str):
choice.append(val); win.destroy()
win = tk.Tk(); win.title("エンジン選択"); win.geometry("300x120")
tk.Label(win, text="文字起こしエンジンを選択してください").pack(pady=10)
tk.Button(win, text="Gemini", width=12, command=lambda: _set("gemini")).pack(pady=5)
tk.Button(win, text="Cloud STT", width=12, command=lambda: _set("stt")).pack()
win.mainloop()
if not choice: raise UserCanceled
return choice[0]
def confirm(file_path: Path, engine: str):
with hidden_root():
if not messagebox.askokcancel(
"実行確認",
f"次の設定で実行しますか?\n\nファイル : {file_path.name}\nエンジン : {engine}",
):
raise UserCanceled
def popup_finish(outputs: list[str]):
with hidden_root():
messagebox.showinfo("完了", "文字起こしが完了しました!\n\n" + "\n".join(outputs))transcriber.py(抜粋)
完全なコードはGitHubリポジトリをご覧ください。
"""
transcriber.py - Gemini / Cloud STT / MP4 対応版
- 入力: WAV/MP3/MP4/MOV/MKV/AVI
- Gemini: 30分 FLAC チャンク(~60MB)
- STT : 55秒 FLAC モノラル(<=10MB, <=60s)
"""
from __future__ import annotations
import csv, os, sys, tempfile, time
from datetime import timedelta
from pathlib import Path
from typing import List
from pydub import AudioSegment
from tqdm import tqdm
import pysrt
import ffmpeg
import google.generativeai as genai
from google.cloud import speech_v1p1beta1 as speech
GEMINI_CHUNK_MIN = 30
STT_CHUNK_SEC = 55
RATE_LIMIT_SLEEP = 5
LANGUAGE_CODE = "ja-JP"
VIDEO_EXTS = {".mp4", ".mov", ".mkv", ".avi"}
class Transcriber:
def __init__(self, file_path: Path, engine: str):
self.src = file_path
self.engine = engine.lower()
stem = self.src.stem
self.out_txt = self.src.with_name(f"{stem}_{self.engine}.txt")
self.out_srt = self.src.with_name(f"{stem}_{self.engine}.srt")
self.log_csv = self.src.parent / f"log_{time.strftime('%Y%m%d')}.csv"
self._init_clients()
def _init_clients(self):
# サービスアカウント鍵の探索とAPI初期化
adc = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
if not (adc and Path(adc).exists()):
for cand in [
Path(sys.argv[0]).resolve().parent / "service_account.json",
Path.cwd() / "service_account.json",
self.src.parent / "service_account.json",
]:
if cand.exists():
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = str(cand)
break
if self.engine == "gemini":
genai.configure()
self.model = genai.GenerativeModel("models/gemini-1.5-pro-latest")
else:
self.speech_client = speech.SpeechClient()
def process(self):
self.audio_source = self._prepare_audio_source()
chunks = self._split_audio()
transcripts: list[tuple[int, str]] = []
for idx, p in enumerate(tqdm(chunks, desc="Transcribing", unit="chunk")):
transcripts.append((idx, self._transcribe_chunk(p)))
self._merge_and_save(transcripts)
self._write_log(len(chunks))
# ... その他のメソッド ...ビルドと配布
ビルド(PowerShell/CMD)
pyinstaller main.py --onefile ^
--add-binary "ffmpeg.exe;." ^
--add-binary "ffprobe.exe;." ^
--name Transcriber生成物:dist/Transcriber.exe
配布(ZIP可)
- 同じフォルダに
Transcriber.exe,service_account.json,ffmpeg.exe,ffprobe.exe - ZIPで配布 → 受信側は展開して EXEをダブルクリックで実行
トラブルシュート(よくある質問)
| 症状 | 原因と対処 |
|---|---|
payload size exceeds the limit(Gemini) |
音声が大きすぎ。FLAC 30分運用で回避。超長尺は File API 検討。 |
Inline audio exceeds duration limit(STT) |
60秒/10MB制限。55秒・FLACで回避。 |
ffprobe not found / MP3で落ちる |
ffprobe.exe が不足。EXEと同フォルダに置く or 同梱。 |
audio_channel_count mismatch(STT) |
2ch→1chへ変換されていない。モノラル化&config=1chで一致させる。 |
| 認証エラー(Gemini/STT) | service_account.json の探索。EXEと同階層 / カレント / 音声ファイルと同階層を順に探索する実装。 |
参考にした公式ドキュメント
- Gemini(Generate Content API):https://ai.google.dev/api/generate-content
- Cloud Speech-to-Text(クォータ):https://cloud.google.com/speech-to-text/v2/quotas
- pydub(ffprobe 必須の注意):https://github.com/jiaaro/pydub/issues/771
- FFmpeg ダウンロード:https://www.ffmpeg.org/download.html
- Tkinter(ファイルダイアログ):https://docs.python.org/3/library/dialog.html
ライセンス・セキュリティ
- サービスアカウント鍵は共有フォルダに置かない(配布先ごとに管理)。漏洩時はGCPで即削除。
- API利用料はプロジェクト合算。同時実行が多い組織はクォータ管理も検討。
まとめ
- 公式ドキュメントに沿った堅実な実装で、社内の非エンジニアも使える運用が可能。
- WAV/MP3/MP4に対応、長尺の現実的なチャンク戦略で制限を回避。
- EXE配布により、ゼロセットアップでの利用を実現。